【本文由小黑盒作者@飞碟AI于05月14日发布,转载请标明出处!】
小米又开源了个新东西,叫 Xiaomi OneVL。
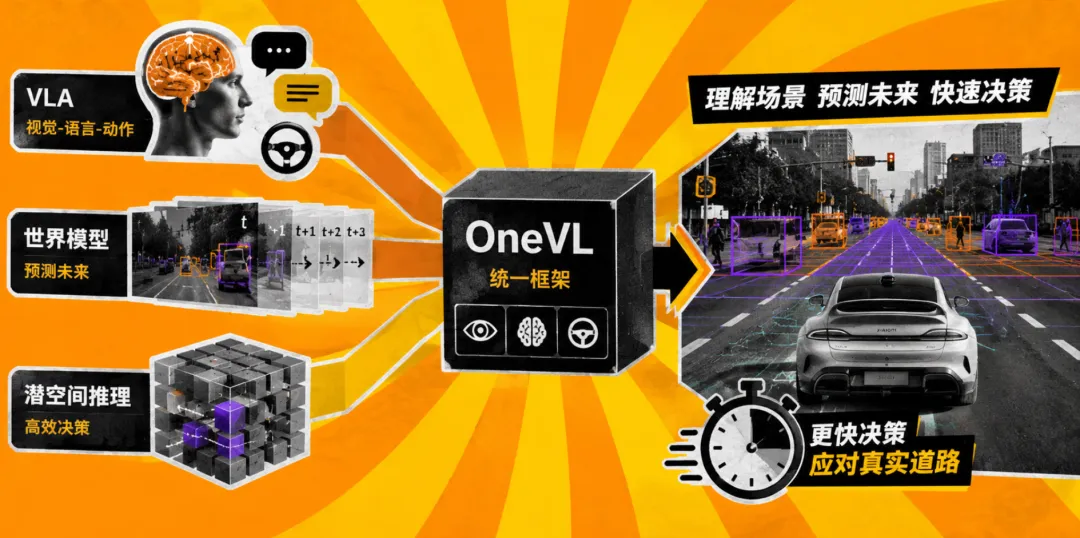
全称挺长,叫一步式潜空间语言视觉推理框架,这次这个框架是给汽车用的:让自动驾驶大模型别再一边开车一边慢吞吞写小作文,先在“脑子里”先想清楚,然后快速给出规划结果。
有趣的是,OneVL 并不是小米从零开始“闭门造车”出来的模型。
它的模型权重基于 Qwen3-VL-4B-Instruct 做增强,视觉分词器则用了 Emu3.5-VisionTokenizer,本质上是在现有开源大模型基础上,往自动驾驶推理这个方向继续深化训练。
OneVL 的目标非常明确:把 VLA、世界模型和潜空间推理三条路线尽量揉进一个框架里,让车既能理解场景、预测未来,又能更快完成决策——毕竟真实道路可不给模型留“慢慢思考”的时间。
过去自动驾驶大模型有个老问题。
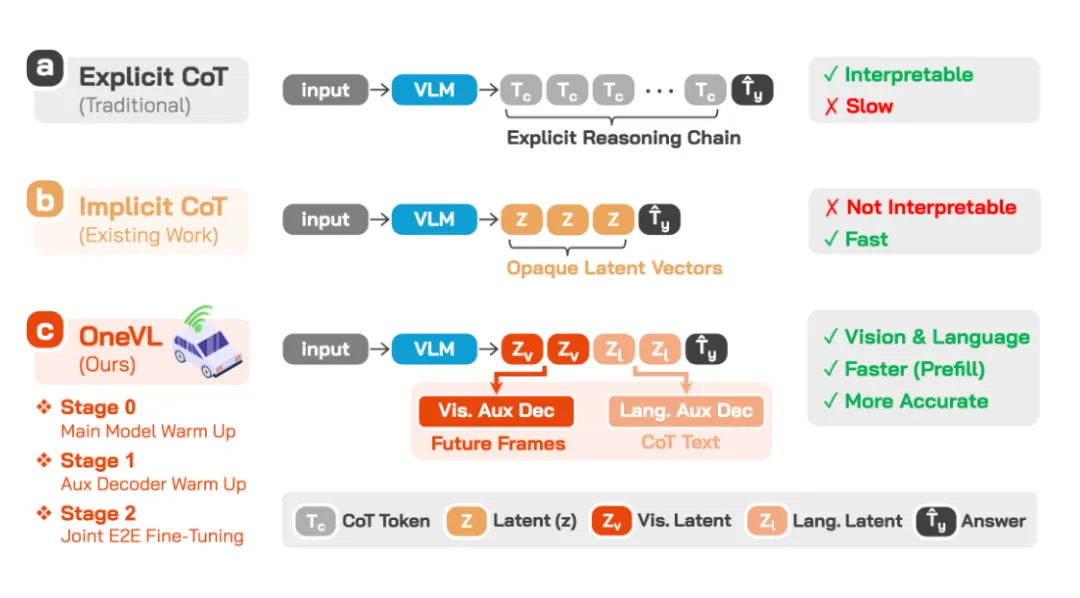
显式 CoT 能提升推理质量,模型会把“为什么这么开”讲出来,但逐 token 生成很慢,车在路上跑,可没空等模型写完内心独白;直接跳过推理输出答案又快,但容易丢掉因果判断。
OneVL 解决的就是这个痛点。
它的做法是把推理压进 latent token,也就是潜空间里的内部表示。
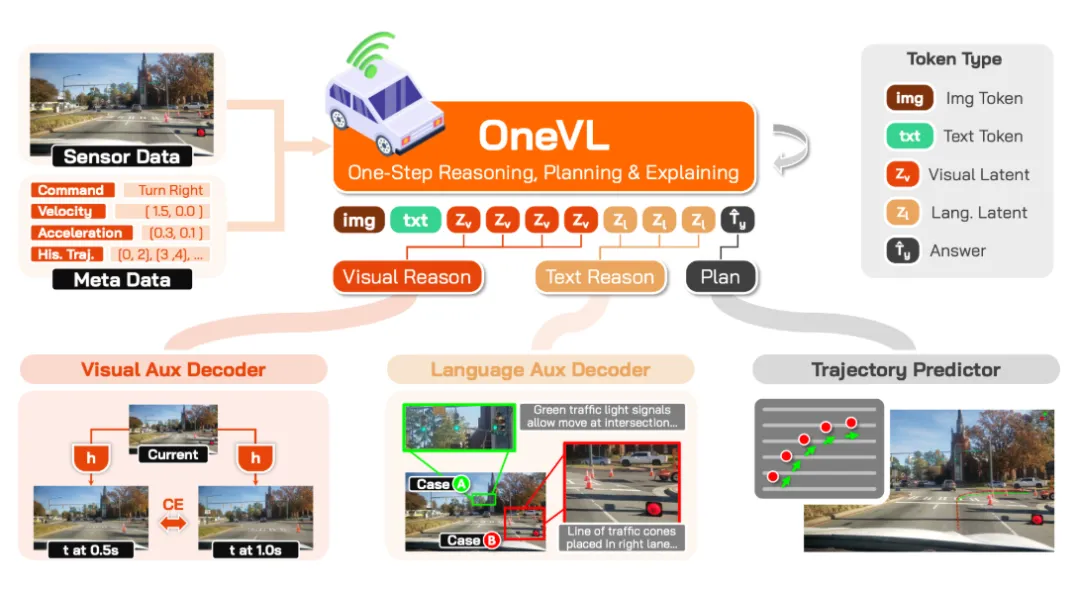
模型直接跳过慢慢输出思考推理过程,先用视觉 latent token 编码场景的物理变化,用语言 latent token 编码驾驶意图。
类似于喊你去描述某个画面,你得慢慢讲,而 OneVL 则可以直接把你脑子里面想到的画面直接抽出来,还准确。
训练时,它还挂了两个辅助解码器,一个负责预测未来 0.5 秒和 1 秒后的画面,一个负责还原人类能读懂的思维链文字。
到了真正推理时,这两个解码器直接丢掉,只保留压缩后的 latent token,一步并行完成推理。
这个设计最有意思的地方在于,它没有只压缩语言推理。
小米团队认为,自动驾驶真正需要压缩的是对未来世界变化的理解。
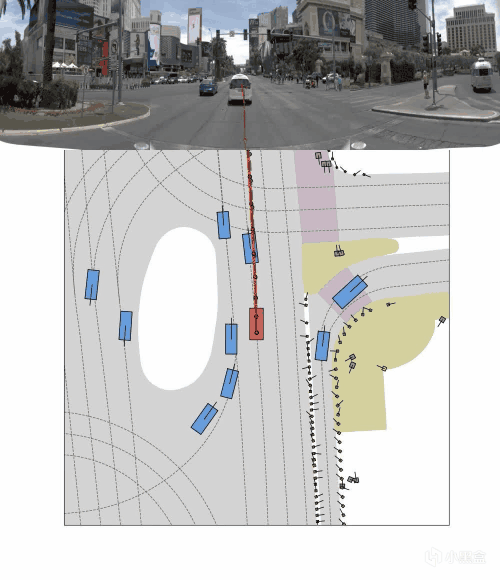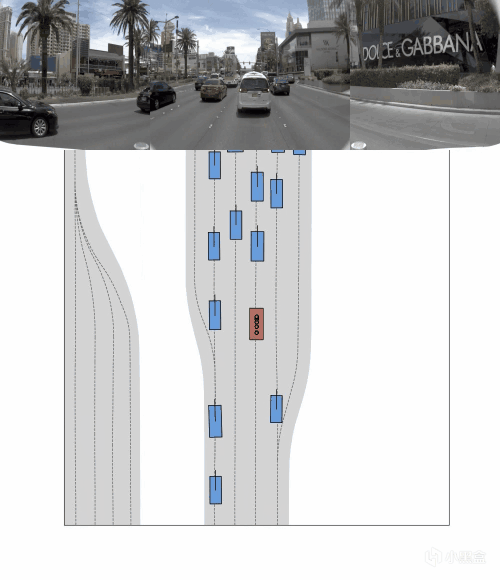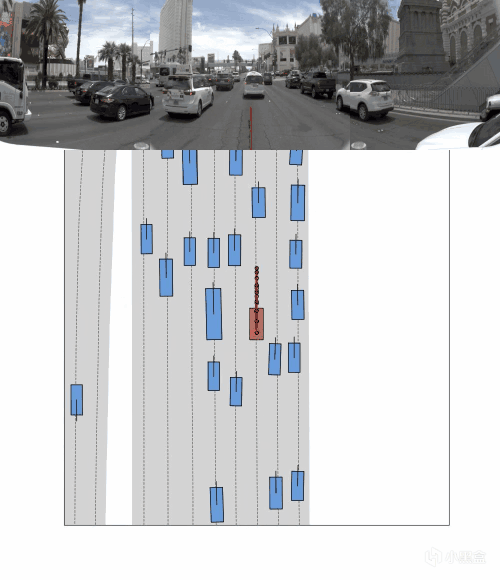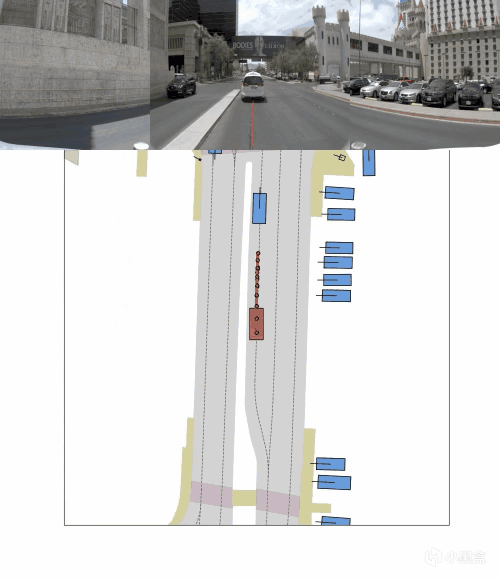
前方车辆怎么动,道路几何怎么变,障碍物会不会切进来,这些比“前方有车所以减速”这种文字总结更关键。
所以 OneVL 的视觉辅助解码器,本质上是在逼模型学会预测未来画面。说得直白点,车不能只会看图说话,还得能脑补下一秒。
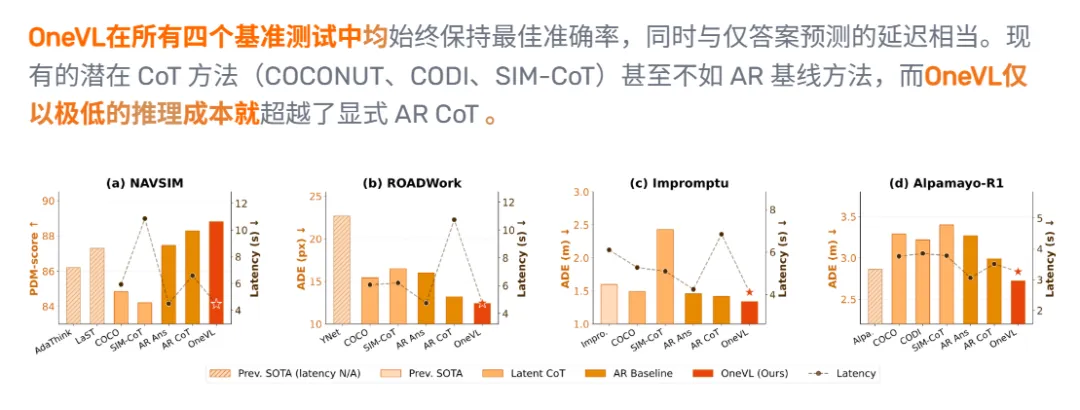
测试数据也确实能打。
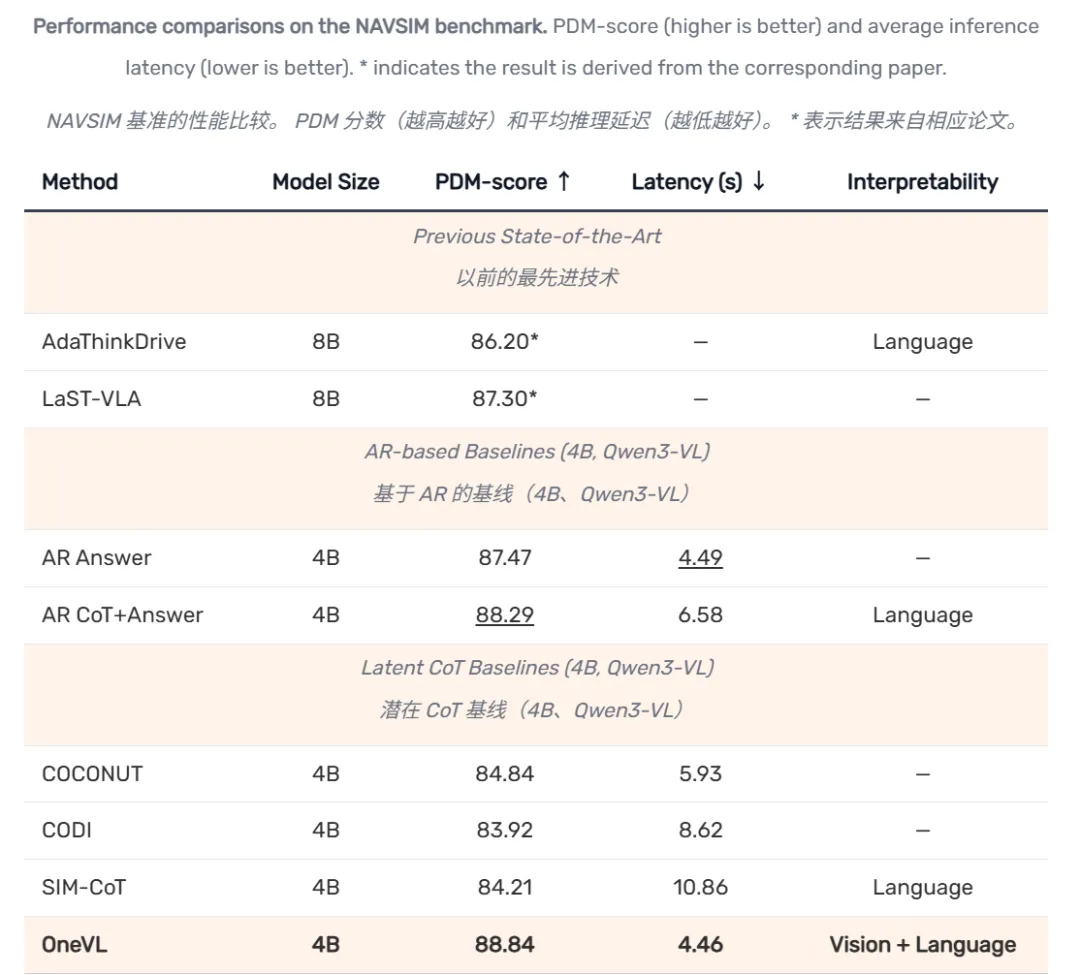
OneVL 在 NAVSIM、ROADWork、Impromptu、Alpamayo-R1 多个基准上刷新潜空间推理方法表现。NAVSIM 上 PDM-score 达到 88.84,高过显式 CoT 的 88.29,延迟却只有 4.46 秒,基本贴近仅答案预测的 4.49 秒。
当然,技术归技术,小米归小米。
OneVL 的意义,可能不在于它今天就能把小米智驾直接推到行业第一,更多是它把一个关键问题摊开了:自动驾驶大模型到底该怎么推理?是继续让模型用文字慢慢解释,还是让模型在潜空间里压缩因果和未来变化?
如果 OneVL 这条路线能继续往下走,车端模型也许会从“看见并模仿”,慢慢走向“理解并预判”。
所以这次 Xiaomi OneVL,客观来讲也确实值得关注,不必神化,也没必要一听小米就先翻白眼。
它解决的是自动驾驶大模型里很现实的问题:精度、速度、可解释性,很难同时要。
至于这条路最后能不能跑通,估计很快会有人拿代码出来复现、对比、挑毛病,毕竟自动驾驶圈最不缺的就是各种吃瓜、质疑与实锤测试,更何况这个项目开源。
接下来就看社区和真实工程表现了。
道正网提示:文章来自网络,不代表本站观点。